¿Has sentido alguna vez la frustración de no ser entendido por el buscador de una página web? Bueno, no eres el único. Se trata de un síntoma usual de los buscadores que no aprovechan el poder de la similitud semántica a través de los embeddings, una herramienta innovadora que a menudo se pasa por alto en el panorama actual de la IA.
El objetivo de este artículo es explicar a un público no técnico qué son los embeddings, cómo pueden beneficiar a las empresas y cómo los aprovechamos en fjord. Siguiendo esa línea, evitaré adentrarme en la ciencia fascinante, pero aterradora, que sustenta esta metodología.
¿Qué problema buscan solucionar los embeddings?
Quién no se ha encontrado buscando en un e-commerce de vestimenta algo parecido a:

Obteniendo los resultados:

Pero luego, al navegar la página manualmente, encontrarse con:

Y pensar: ¿me estás tomando el pelo?
Tristemente, no. El problema es que el buscador está intentando coincidir la secuencia de caracteres presentes en la búsqueda con las secuencias de caracteres presentes en el título o la descripción de los productos de la página (es un poco más complejo, pero mantengamos la simpleza):
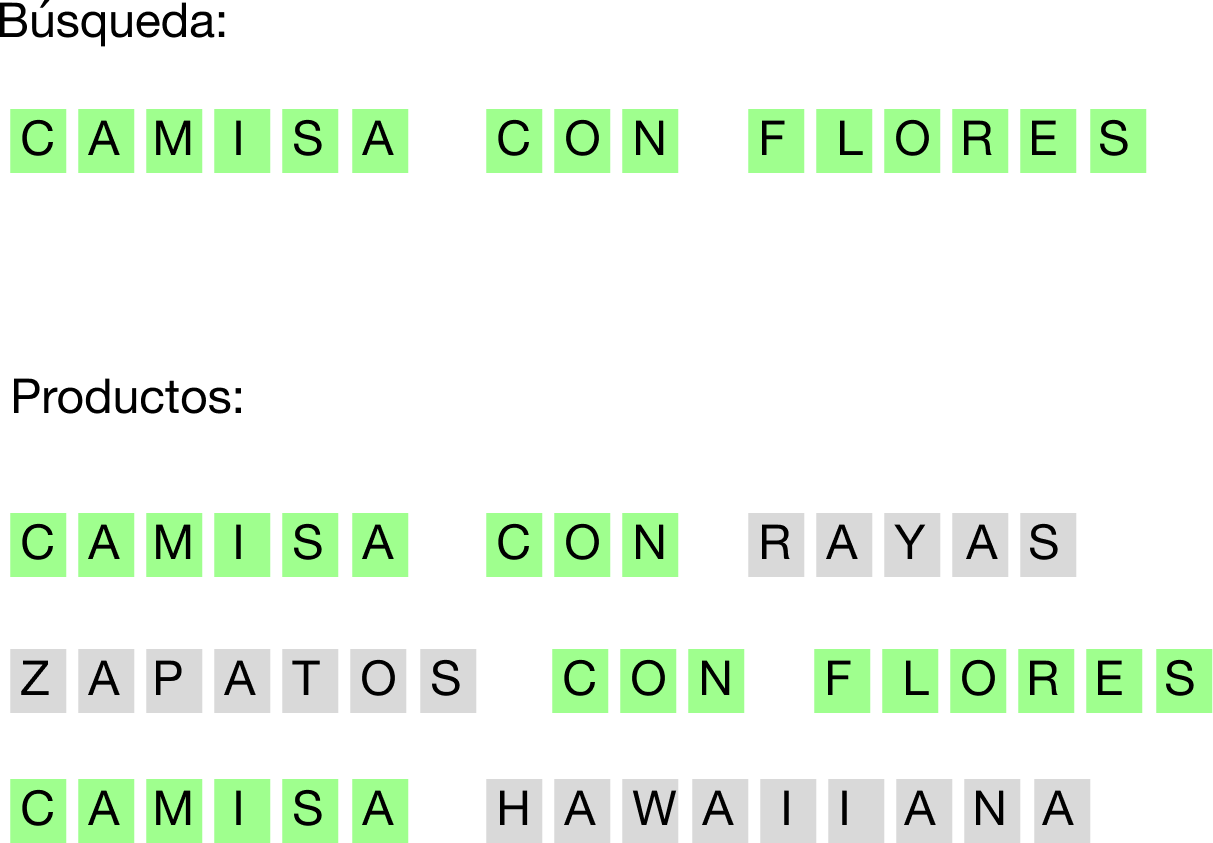
Esta ha sido la forma en que los motores de búsqueda funcionaron durante mucho tiempo. Algunos ingenieros inspirados desarrollaron trucos para mitigar este efecto, como, por ejemplo, agregar palabras clave en la descripción de los artículos para abarcar un espacio de búsqueda mayor:

Ahora, las búsquedas que incluyan “clásica”, “rosa”, “flores”, “blanca”, “vacaciones” o “playa” encontrarán el artículo “Camisa Hawaiiana Rosa”.
¿Pueden encontrar el problema con este tipo de soluciones? Intenten aplicarlo a un catálogo de 500 productos y luego cuéntennos.
Pero… ¿por qué es tan difícil? Porque difiere inherentemente de la forma en que nosotros, los humanos, nos comunicamos. Nos basamos en gran medida en el significado, el sentido y el contexto, no en los caracteres o palabras puntuales presentes en una oración. Para nosotros, la “Camisa Hawaiiana” es una “camisa con flores”, sin necesidad de decir más.
Por suerte, se ha desarrollado una nueva forma de buscar: les presentamos la búsqueda semántica con la ayuda de los embeddings (anglicismo sin traducción).
¿Cómo funcionan los embeddings?
Nota: vamos a evitar caer en la definición técnica para no espantar a los lectores valientes que llegaron hasta aquí con frases como “espacio vectorial altamente dimensional… representación latente… diferencia de coseno…”.
Los embeddings capturan cómo los humanos entendemos conceptos al darle números cercanos a las cosas que tienen un significado similar:

Véase que “banana” está relativamente cerca de “manzana” y “amarillo”, pero lejos de “auto” o “universo”. Ese número que se le da al concepto es lo que se denomina embedding.
Y lo mejor es: hay una “caja mágica” llamada “modelo de embedding” donde uno inserta cierto texto y obtiene el número en cuestión. Esta “magia” en verdad es donde la IA entra al juego, pero no hay necesidad de preocuparse por ello.
Volviendo al ejemplo anterior, en lugar de buscar por caracteres o palabras exactas, buscamos artículos cuyos embeddings estén cerca del embedding de la búsqueda:

¡Bingo! Cualquier e-commerce o sitio con buscador puede utilizar estas “cajas mágicas” para mejorar notablemente la conversión de búsqueda y dar a sus clientes el sentimiento de “ser comprendidos”.
¿Qué más se puede hacer con los embeddings?
Acá el tema empieza a ponerse muy interesante. Ahora que tenemos un mecanismo para traducir lenguaje humano a matemática, podemos aplicar poderosas operaciones algebraicas para lograr un gran rango de resultados. Vamos a adentrarnos lentamente en un terreno un poco más técnico, así que mantengan los ojos bien abiertos.
Clusterización y clasificación
Ahora que, siguiendo el ejemplo anterior, los productos están representados con números, podemos agrupar los números similares. A esta técnica los ingenieros la llamamos “clustering”.
Para describir mejor cómo puede uno beneficiarse de esto, usaremos 2 números para representar los embeddings en lugar de 1. Es decir, los embeddings tendrán 2 dimensiones:
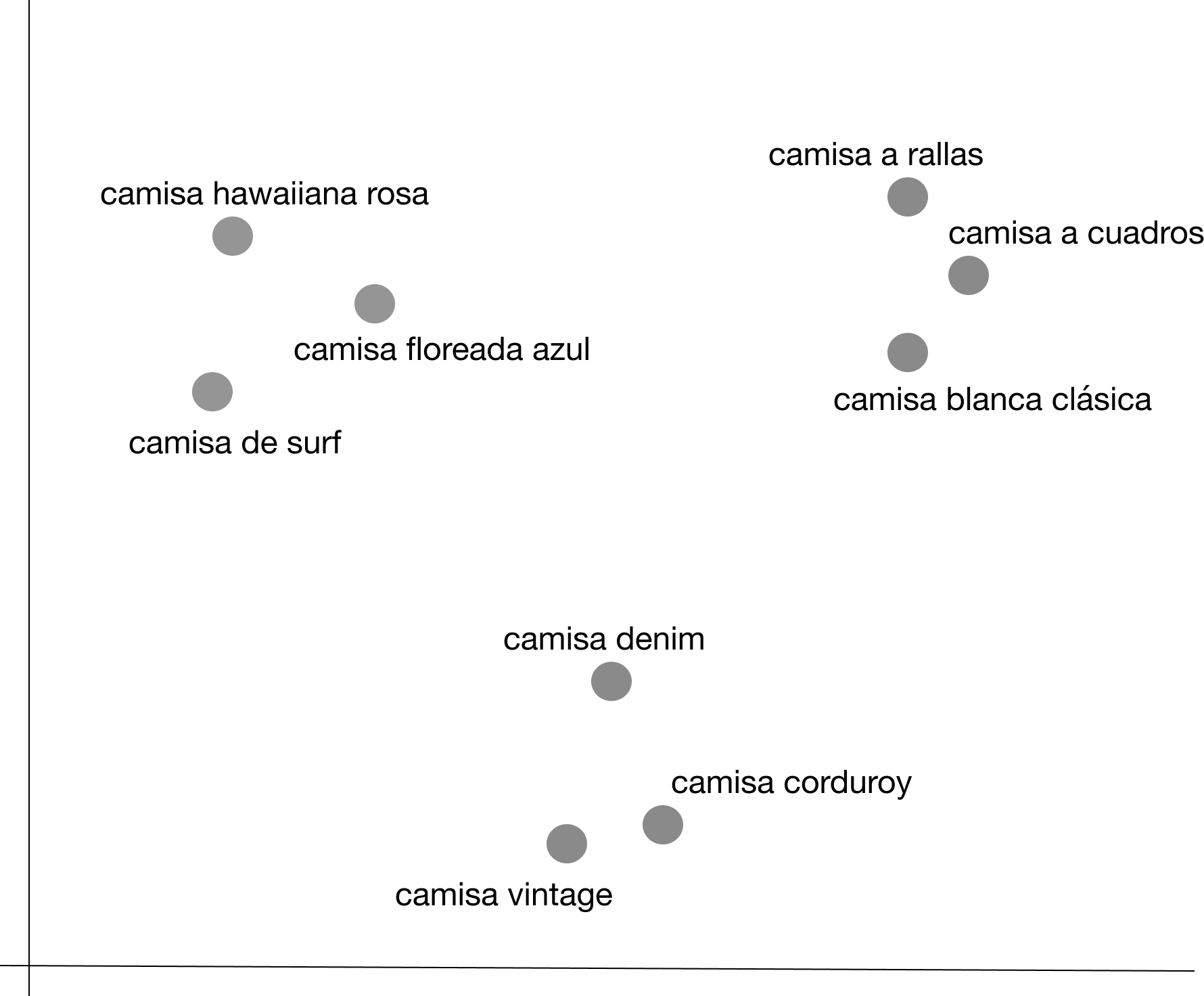
Aplicando un operador matemático, se agrupan los artículos en:
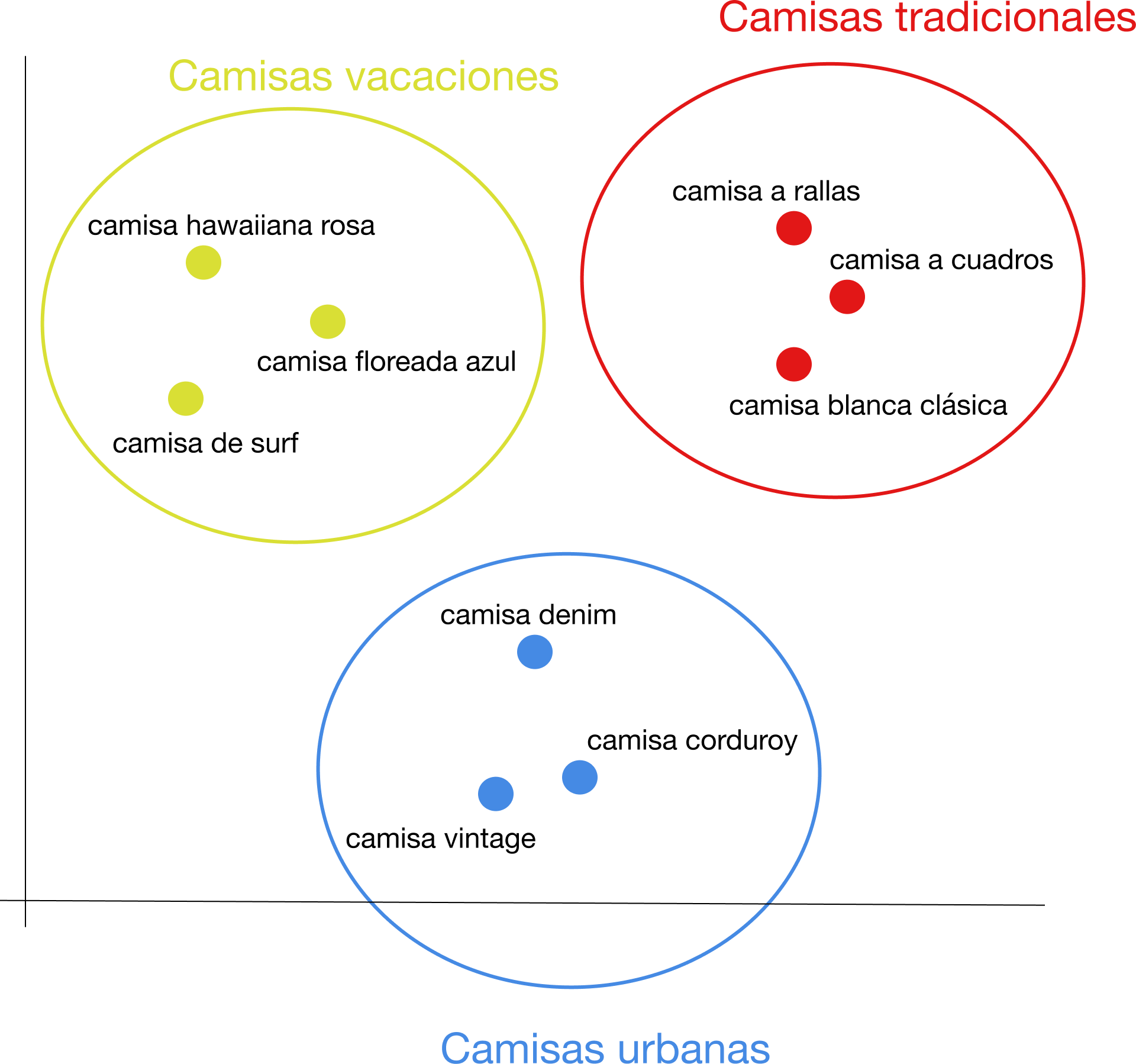
¿Te imaginas lo que esto podría suponer para tu negocio?
- Extrae automáticamente las categorías y jerarquías óptimas de tu catálogo.
- Crea facetas y filtros dinámicos en tu página de resultados de búsqueda para que los usuarios puedan acotar su búsqueda.
- Recomienda artículos similares cuando se encuentren en una página de artículos.
- Identifica los grupos de artículos débiles o saturados de tu oferta.
- Identifica artículos similares en tu catálogo para compartir estrategias de precios y posicionamiento.
- ¡Y mucho más! Nuestra imaginación es el límite.
Visualización y análisis
Ahora que podemos visualizar el catálogo en un gráfico bidimensional, podemos empezar a analizar patrones. Esto podría ser fundamental para enfocarse, por ejemplo, en los patrones de búsqueda de los usuarios y los puntos ciegos del catálogo.
Les vamos a mostrar un ejemplo claro. Dado el catálogo utilizado en el ejemplo anterior, podrías añadirle los embeddings de las búsquedas que no han convertido:
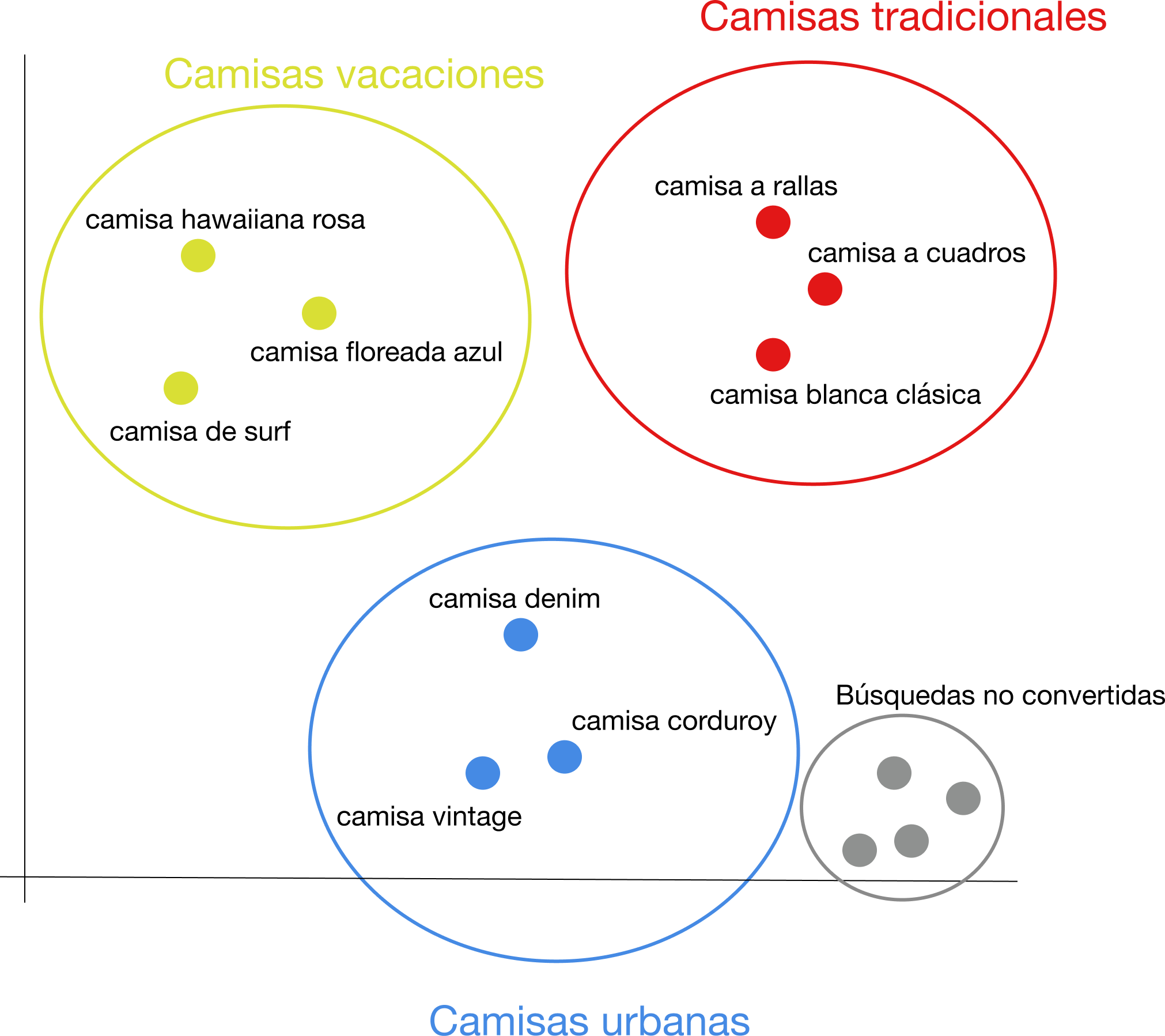
En este ejemplo, parece que los clientes están buscando productos similares a camisas urbanas, pero no están encontrando nada apropiado. ¡Esto podría ser una gran oportunidad de negocio! Después, puedes profundizar en algunas de esas consultas para comprender la categoría subyacente que te estás perdiendo y tomar medidas al respecto.
Búsqueda de documentos
No solo los e-commerce pueden beneficiarse de esta tecnología. Los modelos de embeddings de vanguardia pueden trabajar con palabras, frases, párrafos y hasta documentos enteros.
Esto significa que puedes encontrar en una colección gigante de documentos y contenido exactamente lo que necesitas con lenguaje humano en un abrir y cerrar de ojos.
Usemos un ejemplo real con el que hemos trabajado en fjord: un estudio de abogados. Los abogados suelen necesitar buscar la jurisprudencia que se correlaciona con un caso muy específico. Esto significa buscar entre millones de sentencias, cada una con muchos documentos internos, para encontrar aquellas que sean, de alguna manera, similares al caso que están tratando. Una verdadera pesadilla.
Pero ya no más con el poder de los embeddings. El primer paso es pasar todos los documentos (jurisprudencia) por la “caja mágica”, obteniendo así un número para cada uno. Volquemos de vuelta todo en un gráfico:

Ahora simplemente podemos preguntar por la jurisprudencia que está semánticamente relacionada con nuestro caso. Supongamos que el tema es: “Derechos violados de los pueblos indígenas de la Patagonia”. Pasamos textualmente ese titular por la “caja mágica” y dejamos que el sistema busque los documentos más cercanos:
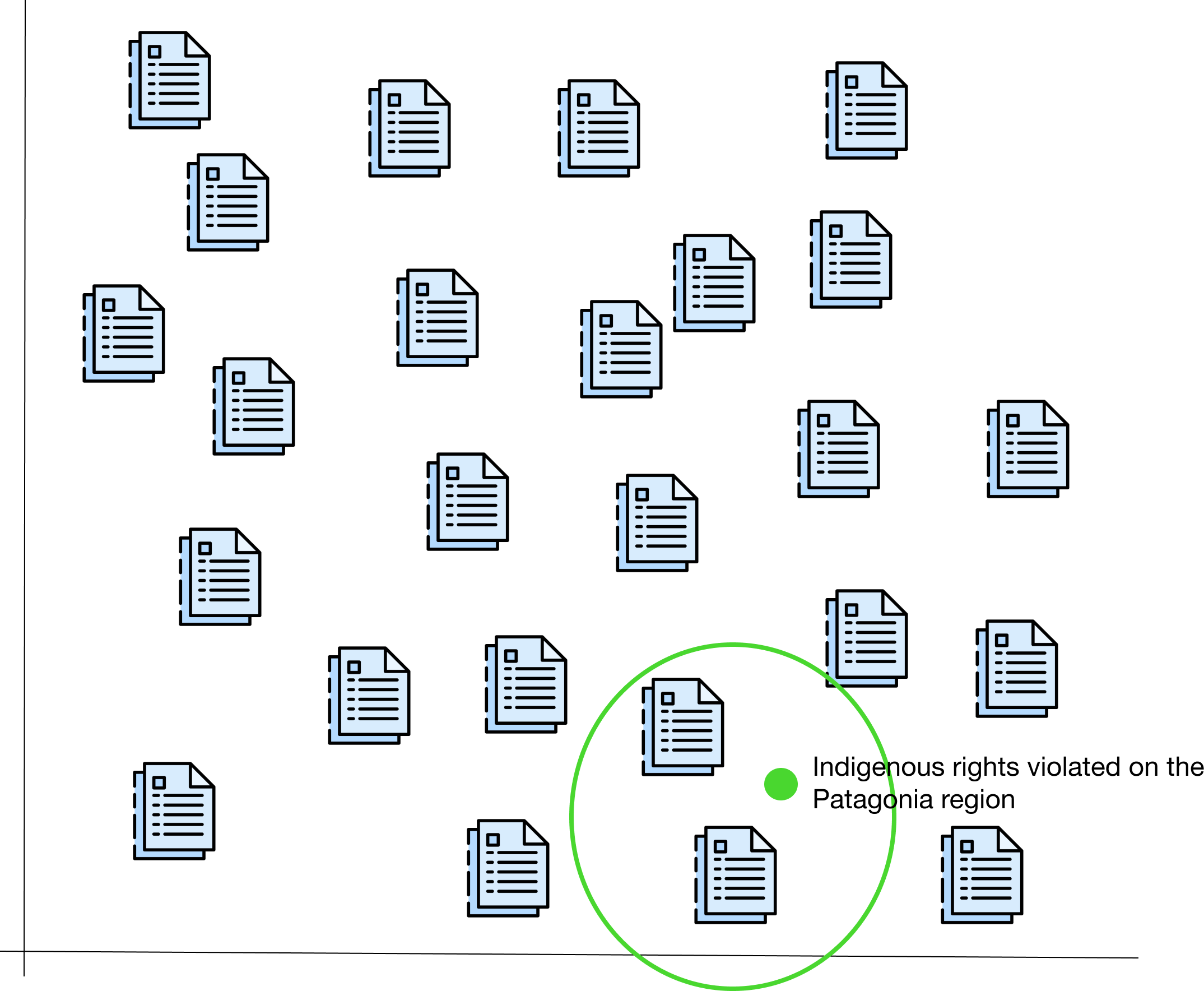
¡Horas de investigación salvadas con el poder de los embeddings y la búsqueda semántica!
Una vez más, las aplicaciones de esta tecnología son interminables, y en fjord te guiamos en cómo puede ayudar mejor a tu negocio.
Para los más curiosos, esto es exactamente lo que se hace en RAG para mejorar el rendimiento de los LLM, proporcionando un corpus de documentos relevantes como contexto para el prompt. Profundizaremos en esto en un caso de estudio posterior.
Embeddings multimodales
En la frontera de esta tecnología se encuentra el espacio multimodal. Esto significa que las imágenes, los audios, los textos y los videos tienen embeddings (números) comparables.
Esto es extremadamente poderoso, ya que se puede aplicar todo lo que hemos comentado anteriormente dentro y entre todas estas modalidades. Por ejemplo:
- Buscar imágenes, videos o audios con lenguaje humano, basándose completamente en el contenido del archivo.
- Comparar y agrupar imágenes o videos automática y óptimamente. Piensen en todo el poder de recomendación y análisis que esto desbloquea.
¿Cuál es la trampa?
La trampa aparece en la complejidad ingenieril de desarrollar y mantener dicho sistema, pero, afortunadamente para ustedes, fjord se encarga completamente de ello. Esta complejidad se debe a:
- Los embeddings no son solo números, son vectores. Piensa en ellos como una lista de números con más de mil elementos. Calcular la similitud entre números (diferencia) es mucho más fácil que con vectores (distancia y orientación en el espacio).
- Los modelos de embedding, por mágicos que parezcan, no son perfectos. En medio de todo esto pueden aparecer algunos resultados extraños, por ejemplo, “banana” más cerca de “rojo” que de “amarillo”. Para asegurarse de que los resultados sean correctos y coherentes, se deben filtrar los resultados de la búsqueda con otro modelo de IA, el ReRanker, para mostrar al usuario solo los artículos recuperados correctos.
- Hay casos en los que la búsqueda tradicional por palabras o caracteres es útil. Piensa, por ejemplo, en los nombres de marcas: si alguien busca “Coca-Cola”, quiere “Coca-Cola” y no “Pepsi”. Por eso, lo ideal es utilizar ambos enfoques en paralelo y, posteriormente, combinar y filtrar los resultados. Como puedes imaginar, esto conlleva cierta sobrecarga de ingeniería.
- La velocidad y la latencia son muy importantes cuando se trata de búsquedas. Cada pequeña parte del sistema debe optimizarse al máximo para dar la sensación de “inmediatez” a los usuarios. Crear el embedding, calcular la distancia algebraica entre miles de otros embeddings, recuperar el más cercano, filtrar los resultados incorrectos y mostrar los correctos en unos pocos milisegundos.
- Los embeddings deben actualizarse constantemente: si cambia un título o una descripción, se añade un nuevo artículo o se elimina uno, hay que asegurarse de que todo se recalcule para seguir obteniendo resultados significativos.
- Los embeddings deben residir en bases de datos especiales denominadas “bases de datos vectoriales”. Por lo tanto, añaden un componente más al sistema.
- Los modelos de embedding, las famosas “cajas mágicas”, están en constante desarrollo y mejora. Se debe seguir investigando y actualizando el sistema para obtener la mayor precisión y el mayor recall posibles.
- Cuando se trabaja en un sector especializado, con vocabulario y jerga específicos, los modelos de embeddings de uso general dejan de ser útiles. En esos casos, estos modelos deben ajustarse y volver a entrenarse con nuevos datos relacionados para especializarse en el tema en cuestión.
En fjord technology sabemos cómo navegar por estas complejidades para que su negocio y sus clientes puedan disfrutar únicamente de sus beneficios.
¿Quieres saber más de las tecnologías mencionadas?
Chequea los recursos favoritos que usamos en fjord: